
tranSMART: A Year of Innovation and Growth of an Open Source Community
By Dan Housman
tranSMART is an open source framework for knowledge management of translational research data including both molecular information such as DNA, RNA, and proteins along with clinical information such as clinical trial outcomes and patient demographics and disease conditions. Workshops for the tranSMART user community took place prior to at during the Bio-IT Conference.
“Be conservative in what you do. Be liberal in what you accept from others.” John Postel, author of the TCP protocol
The software was originally produced for internal use by Johnson & Johnson using a variety of existing open source tools such as i2b2, a government funded open source project led by a team from Harvard affiliated hospitals. The first open source release of the software was established in early 2012 and the past year provides a window into the evolution of a platform and critical success factors and risks for an open source project of this type
The general objectives of the software are to support generation of information for key questions in drug discovery research that have been difficult to answer due to the silos that form around clinical data sets for competitive, regulatory, and compliance reasons. Such questions include identification of key biomarkers such as a genetic different between responders and non-responders to a drug due to underlying biological differences that aren’t apparent. Another question is to determine which disease to focus for a drug that shows promise in a number of therapeutic opportunities. Cancers and immunological diseases each show a wide variety of phenotypes (observable diseases) such as the tissue the cancer originates from such as lung cancer vs. leukemia. These markers or indication selection activities are particularly valuable for pharmaceutical companies seeking to design clinical trials where success criteria of high cost studies represents a binary result of a large financial investment. The pharmaceutical companies and health systems caring for patients have a wealth of information to support these decisions if they can use and share data.
The tranSMART open source project provides a free, open software package for integrating and combining this information. A set of pilot projects were implemented prior to the release of the open source version including 3 pharmaceutical organizations. Upon the launch of the software in 2012 a meeting was held among early participants where the following issues were raised as primary concerns by the group:
- Lack of a sustainability strategy
- Groups committing updates to the code vs. downloading the code were expected to be limited
- Features: Enable cross study analysis + curation complexity/needs, user Interface Gaps in terms of usability and utility, Resolve gaps in underlying systems (i2b2 interfaces for genomics were not available)
- Prove the ROI (Return on Investment) of translational knowledge mgmt. tools
- Data sharing concerns reliability/governance/etc.
The first year of adoption has included the following experiences.
Sustainability
The open source project launched with version .9 beta in February of 2012 with the first open source license attached to the software distributions available on github. Multiple consortia have begun to adopt the software as a knowledge management framework. The largest consortium is the IMI (International Medicines Initiative) who have embarked upon eTRIKS, a European knowledge management framework to support the organization’s many research initiatives (with over $2B Euro of research investment). The IMI consortium has acted as an anchor to give other groups confidence in the sustainability and investment in the platform and initiated interest in the platform in 2009 to produce a funded initiative (23.8M Euros over 5 years).
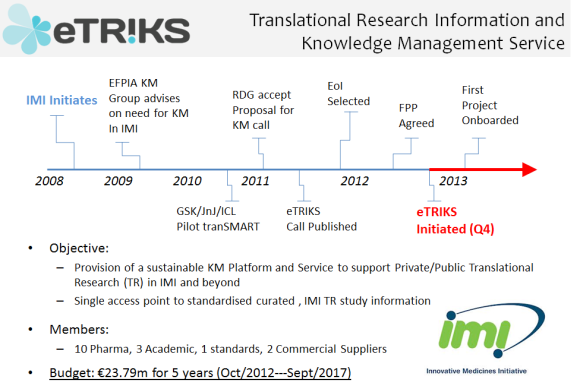
Other consortia that selected tranSMART include TraIT, a national research initiative in the Netherlands, and One Mind, a US based non-profit focused on research into neurological diseases such as PTSD, TBI, and Multiple Sclerosis. The addition of consortia created independent projects but not a clear sustainability model for a core function.
An additional initiative towards sustainability was led by Michigan University established the tranSMART Foundation, intended to become a 501c3 US based non-profit foundation. By forming a 501c3 organization the group can perform fund raising activities towards establishing core programming and educational resources. Michigan also provided leadership by establishing initial resources for a port of the software’s database back-end tools from Oracle to Postgres to allow for additional activities.

The general model to be commercial friendly to enable sustainability was borrowed from lessons from non-research open source models such as Drupal and Linux. Although the licensing is a GPL 3 model establishing a copyleft framework for enhancements organizations are working to form commercial ways to service specific needs of tranSMART adopters. A number of additional organizations working in the translational research domain have also committed to the open model including Thomson-Reuters, Spotfire, BioFortis, IDBS, Elsevier, and The Hyve. Each group brings their own perspective to offer capabilities ranging from licensed subscription content to new analytical modules. The view that has begun to form is of an Android type model for engagement where the core platform is open and extensions and services can be added by 3rd parties.
My organization, Recombinant By Deloitte, constructed the initial code base for the software. We are among multiple groups involved in forming commercial models that extend the software with both services and packaged software extensions. Among the commercial changes during the year included the acquisition of our team into the broader Deloitte organization which brought new reach due to a large scale consulting organization incorporating the software into their available offerings.
Code updates/committers and the community responses to feature gaps
The community includes both the business management involved in research informatics and the software development teams constructing the software. The software teams have used tools such as Google Groups and github to organize discussions and source code integration. Business and scientific team members have focused on LinkedIn as a collaboration tool. The community had regular monthly calls to support transparency regarding what other groups were experiencing. The community grew over the course of the year from 141 to 264 members on the LinkedIn group over the course of the year. The software for multiple implementations were maintained in local source code repositories each managed by the adopting site. Specific enhancements were made by groups such as Jannsen Pharma who introduced an updated faceted search view and shared an early version that was used by Pfizer to produce the user interface for a GWAS data set exploration tool. Work from a project executed at Millennium incorporated an R plugin environment to enable statistical access to underlying data sets. The result culminated with contribution of the faceted search tools by Jannsen and Pfizer to an open git branch.
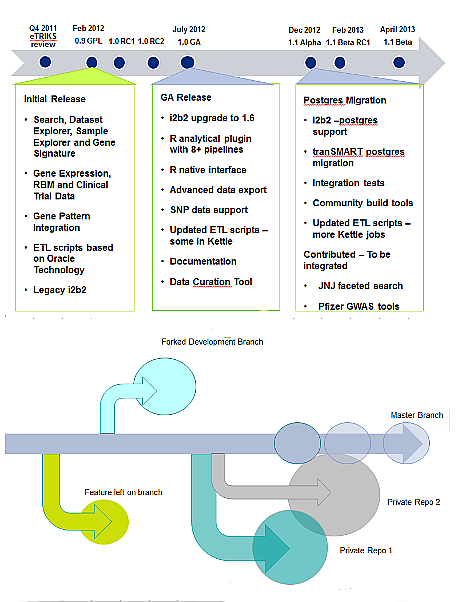
2012 – 2013 tranSMART open source timeline regarding enhancements and releases and repository strategy for branching and merging the tranSMART code using github.
Among the next steps though is to integrate the contributed code into the main branch since contribution of multiple new open branches doesn’t constitute an integrated main branch. Because the implementations at pharma groups are constructed on an Oracle database these also require some porting to integrate them onto the main branch including Postgres. An additional set of features were added by the University of Michigan and Thomson Reuters to add new plugins to searches executed by users. The result was identification that the original architecture was not inherently conducive to modular addition of new feature sets in the search tool. This is compounded by the general overall concern that with many sites adopting the software and a non-central method for managing code governance that the software will diverge into multiple versions that can’t be reconciled. In addition to this there were scalability issues raised in the group regarding analysis of large data sets from genomics. As a result among a major focus agreed upon by all parties involved in the development was to establish a refinement of the architecture to ensure a more modular system to enable the open development to continue with clearer APIs and plugins identified. Groups continuing new extensions are now working to refactor the core software to add APIs and configuration management to enable their extensions rather than placing more strain on custom ‘hacks’ in the core code base. Groups area also adding a new data store using Hadoop to handle the high scale needs for genomics. Some sites are also looking into additional technologies to resolve high scale/high performance applications such as the SAP Hana in memory database and MPP tools such as GreenPlum and Netezza.
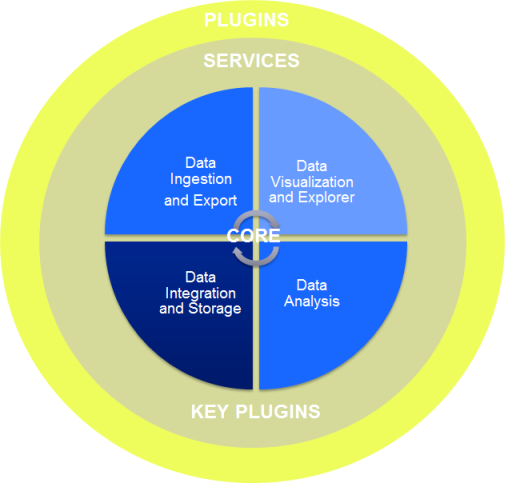
Annual meeting and new concerns for 2013-2014
The Bio-IT World 2013 trade show provided an ideal bookmark on one year of activity on tranSMART. A number of activities were organized including a pre-conference workshop attended by over 35 people, 3 sessions with tranSMART during the overall conference, and an evening networking event. The face to face interaction helped the group to unify and understand the current dynamics of the growing community. Among the issues shared among community members towards the upcoming year are the following areas.
- Better proof of ROI at adopter sites
- Customer centric engagement (end-users)
- Adoption and adaptation among AMC/Medical Center sites
- Demonstrated core API development
- 501c3 Foundation funded appropriately to co-ordinate and drive progress
- Frequent integration among branches into main branch
- Commercial expansion or other models to build to stable sustainability
- Increased data availability
- Stronger/Faster genomics content, platforms, and analytics integration
These represent the major challenges for the emerging platform. Among the newly discussed issues are ones that face all software as the audience expands beyond a small group. The issue of user engagement and measuring the value of the software systems and data sets are key themes towards ensuring the project is an overall success. Furthermore the need to manage fragmentation, modularization, scalability, and affordability of capabilities are dominant themes in the dialog towards future planning. The tranSMART Foundation has taken a central role in leading the dialog around co-ordination such as convening the community, building code governance, and roadmap planning. But there are still many efforts that happen as organic extensions occur in individual groups both commercially and through academic collaboration efforts. We have seen the first stages of evolution of an open source project and can clearly see many areas of risk going forwards. But the benefits to institutions participating including adopters, funding sources, and commercial enterprises are the key to having sufficient resources and leadership engaged towards overcoming those risks.
Contributor
 Dan Housman is Chief Technology Officer of Recombinant By Deloitte. Prior to co-founding Recombinant By Deloitte, Dan founded a company that pioneered Partner Relationship Management (PRM) and ecommerce applications.
Dan Housman is Chief Technology Officer of Recombinant By Deloitte. Prior to co-founding Recombinant By Deloitte, Dan founded a company that pioneered Partner Relationship Management (PRM) and ecommerce applications.
Read more…
 Nitish V. Thakor is a Professor of Biomedical Engineering at Johns Hopkins University, Baltimore, USA, as well as the Director of the newly formed institute for neurotechnology, SiNAPSE, at the National University of Singapore.
Nitish V. Thakor is a Professor of Biomedical Engineering at Johns Hopkins University, Baltimore, USA, as well as the Director of the newly formed institute for neurotechnology, SiNAPSE, at the National University of Singapore.  For about eight years, Ian Lumb had the good fortune to engage with customers and partners at the forefront of HPC plus Grid and Cloud computing. For all but one of those eight years, Ian was employed by Platform Computing Inc...
For about eight years, Ian Lumb had the good fortune to engage with customers and partners at the forefront of HPC plus Grid and Cloud computing. For all but one of those eight years, Ian was employed by Platform Computing Inc...  Dan Housman is a software veteran with a demonstrated track record of providing valuable and innovative decision support systems to large, complex organizations...
Dan Housman is a software veteran with a demonstrated track record of providing valuable and innovative decision support systems to large, complex organizations...