
“IBM Watson + Data analytics”: a big data analytics approach for a learning healthcare system
By Chalapathy Neti, Shahram Ebadollahi, Martin Kohn, David Ferrucci
IBM Watson is a new class of industry specific analytical solutions that leverages deep content analysis and evidence based reasoning to accelerate and improve decisions and optimize outcomes.
A learning healthcare System: Global goals for the transformation of healthcare include promoting evidence-based decision making. Success will require substantial changes in methods by which clinical evidence is aggregated and applied. Substantial investments in health information technology, comparative effectiveness research, healthcare quality and value, and personalized medicine supporting these efforts have had sufficient impact to create optimism for the future. An emerging initiative, and one which integrates these converging approaches to improving healthcare, is “rapid learning healthcare.” [1]. In this framework, routinely collected real-time clinical data drive the process of scientific discovery, which becomes a natural outgrowth of patient care. In this brief, we argue that a hybrid approach that combines knowledge analytics (the ability to extract evidence from pre-curated on-line knowledge sources; e.g. text books, clinical trials, guidelines, etc.), enabled by technologies like IBM Watson, in combination with data-driven analytics (the ability to extract insights and generate evidence from patient observations captured in the collective institutional data, as a natural outgrowth of patient care) is a promising direction to enable a rapid learning healthcare system.
DeepQA, the technology behind the Watson, is a general purpose software framework for understanding and answering users natural language questions over a combination of large volumes of “as-is” natural language text and formal knowledge [2] Technically, DeepQA implements a massively parallel, probabilistic evidence-based language analysis and search system (Figure 1). It deeply analyzes and understands users questions, reviews many text-like sources in the background to generate potentially 100’s or 1000’s of hypotheses and possible responses. It then considers additional thousands of pieces of text-based and fact-based evidence in support or in refutation of those hypotheses. It uses text analysis and formal reasoning to score the evidence, ultimately producing a ranked list of responses and associated confidences (confidence that those answers are relevant to the issue in question). DeepQA has been used to build Watson the computer system that beat winning players at Jeopardy! which required high degrees of accuracy and confidence over a very broad domain of general knowledge. Watson, in its Jeopardy! debut demonstrated the ability to scan information in 1 million books or about 200 million pages of data, analyze it and respond with answers in less than three seconds. By integrating domain-specific textual knowledge sources with domain-specific structured knowledge and inferences systems (taxonomies, databases and/or knowledge bases), DeepQA/Watson is being specialized to target areas like healthcare, Financial services, Customer Intelligence, etc.
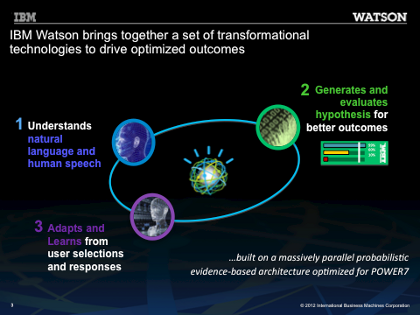
Figure 1: IBM Watson brings together a set of transformational technologies to drive optimized outcomes
Application to Healthcare: IBM recently engaged in partnerships with Wellpoint (the largest healthcare insurer in the US) and Memorial Sloan Kettering Cancer Center (MSKCC) to create commercial applications for Watson in Healthcare. With Wellpoint, Watson will help nurses make decisions about requests for prior authorization of payment. At MSKCC, Watson will be taught about Oncology so that it can help with diagnostic and therapeutic decisions in cancer. Both projects rely on Watson’s ability to automatically understand the questions of concern, incorporate patient specific information, review guidelines and other literature to generate suggestions for the clinician to consider. In the prior authorization case Watson’s ability to consistently and automatically evaluate the request against guidelines and the patient information, without boredom or fatigue, makes the process more efficient and reliable. In Oncology, Watson will read and understand patient information, guidelines, and clinical literature to make its recommendations, enabling the delivery of the latest knowledge to the point-of-care.
Data-driven analytics: The Gold Standard for generating evidence, treatment guidelines in medical practice has been Randomized Controlled Trials (RCT). There is an ongoing debate on the best way to use RCT results in clinical practice, especially the external validity of the results of such studies. Due to the restrictions imposed by inclusion/exclusion criteria, RCTs demonstrate efficacy of a treatment in a restricted ideal setting, not effectiveness, which has to do more with performance of a treatment option in the actual clinical setting. For demonstrating effectiveness non-randomized studies are needed. Observational studies aim at comparing groups of patients subject to different, non-randomly assigned treatments. Due to the increasing availability of large patient population records, such observational studies are gaining credence. We believe that a central analytics component to enable such studies is patient similarity analytics, which addresses the issue of how to identify groups of patients that are clinically similar to the current patient, given longitudinal medical records of both the current patient and those of other patients in the population. In addition, the insights drawn from the cohort of similar patients can be used to provide support for diagnostic, treatment and care management, particularly for complex patients with multiple co-morbidities who don’t fall neatly into categories defined in published clinical practice guidelines. Our lab has developed novel information representation, integration, machine learning and analytics methodologies that can be used to create homogenous patient cohorts from retrospective data, using patient similarity, and several examples of analytics to generate hypothesis and insights on personalized diagnosis, treatment, clinical and cost effectiveness [3] from observational data collected as an outgrowth of patient care.
IBM Watson + data-driven analytics as a framework for learning healthcare: Knowledge driven, enabled by IBM Watson, and data driven strategies reflect two ends of the spectrum. More specifically, a knowledge driven approach is based on evidence of varying value, guidelines, and experts’ opinions, while a data driven approach is solely based on the observational data. Hybrid strategies that start with prior knowledge then extend to a more comprehensive model by selectively including an additional set of features that both optimize prediction and complement knowledge based features, are proving to be compelling. In our lab, we are evaluating various hybrid approaches to combining knowledge and data-driven approaches to quantitatively judge the optimal strategies for combining two complementary strategies for model building.
For example, the ability to identify the risk factors related to an adverse condition, e.g., heart failures (HF) diagnosis, is very important for improving care quality and reducing cost. Existing approaches for risk factor identification are either knowledge driven (from guidelines or literatures) or data driven (from observational data). No existing method provides a model to effectively combine expert knowledge with data driven insight for risk factor identification. Risk factors for Heart Failure have been previously studied and documented from clinical knowledge like literature including Age, Hypertension, Diabetes, Valvular heart disease, Coronary heart disease, and Chronic kidney disease. The advantage of a knowledge driven approach is that interpretability of the risk factors is grounded in established evidence and based on variables that are reasonably well understood. However, not all risk factors have been identified, nor the combined effects of multiple risk factors fully characterized. In a recent study [4], we demonstrated that by including additional data driven risk factors, the task of early disease onset prediction for Heart failure was significantly (over 20%) improved in comparison to a purely knowledge-based risk factors.
These results suggest that combining “knowledge analytics” enabled by Watson/DeepQA technology with “data-driven analytics” is a promising approach for a rapid-learning healthcare system: that is, combining care delivery knowledge automatically extracted from human curated knowledge sources (e.g. textbooks, clinical trial literatures, Guidelines, etc) with institutional insights discovered from routinely collected real-time clinical data, as a natural outgrowth of patient care, can be a powerful platform for continuously learning, evidence-based healthcare system.
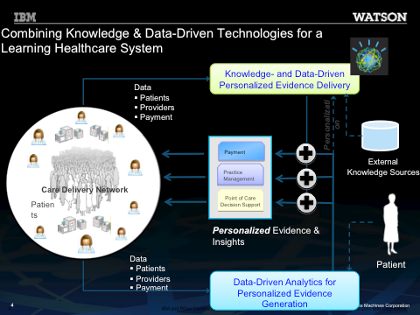
Figure 2: Combining Knowledge & Data-Driven Technologies for a Learning Healthcare System
For Further Reading
1. A P Abernethy, L M Etheredge, P A Ganz, P Wallace, R R German, C Neti, P B Bach, S B Murphy. “Rapid-learning system for cancer care”, Journal of Clinical Oncology, American Society of Clinical Oncology, 2010.
2. D. Ferrucci, E. Brown, J. Chu-Caroll, J. Fan, D. Gondek, A. Kalyanpur, A. Lally, J.W. Murdock, E. Nyberg, J. Prager, N. Schlaefer, and C. Welty, Building Watson: An Overview of the DeepQA Project, AI Mag., vol. 31, no. 3, pp. 59-79, Fall 2010.
3. David Gotz, Harry Stavropoulos, Jimeng Sun, Fei Wang., “ICDA: A Platform for Intelligent Care Delivery Analytics”, submitted to AMIA, 2012
4. Jimeng Sun, Jianying Hu, Dijun Luo, Marianthi Markatou, Fei Wang, Shahram Edabollahi, Steven E. Steinhubl, Zahra Daar, Walter F. Stewart, “Combining Knowledge and Data Driven Insights for Identifying Risk Factors using Electronic Health Records”, submitted to AMIA, 2012.
 Dr. Martin Kohn is Chief Medical Scientist for Care Delivery Systems in IBM Research. He is a leader in IBM's support for the transformation of healthcare, including development of personalized care, outcomes-based models and payment reform.
Dr. Martin Kohn is Chief Medical Scientist for Care Delivery Systems in IBM Research. He is a leader in IBM's support for the transformation of healthcare, including development of personalized care, outcomes-based models and payment reform.  Chalapathy Neti is currently the Director and Global Leader, Healthcare Transformation, at IBM Research. In this role he leads IBM's global research, spanning 9 worldwide labs, on information technology innovation for healthcare transformation.
Chalapathy Neti is currently the Director and Global Leader, Healthcare Transformation, at IBM Research. In this role he leads IBM's global research, spanning 9 worldwide labs, on information technology innovation for healthcare transformation.  Dr. Shahram Ebadollahi is the senior manager of the Healthcare Systems and Analytics Research at IBM T.J. Watson Research Center in New York. He and the team of scientists working with him conduct research in the broad area of health informatics.
Dr. Shahram Ebadollahi is the senior manager of the Healthcare Systems and Analytics Research at IBM T.J. Watson Research Center in New York. He and the team of scientists working with him conduct research in the broad area of health informatics.  David A. Ferrucci is an IBM Fellow and the Principal Investigator for the DeepQA Watson/ Jeopardy! project. He has been at the T. J. Watson Research Center since 1995, where he leads the Semantic Analysis and Integration Department.
David A. Ferrucci is an IBM Fellow and the Principal Investigator for the DeepQA Watson/ Jeopardy! project. He has been at the T. J. Watson Research Center since 1995, where he leads the Semantic Analysis and Integration Department.  Nitish V. Thakor is a Professor of Biomedical Engineering at Johns Hopkins University, Baltimore, USA, as well as the Director of the newly formed institute for neurotechnology, SiNAPSE, at the National University of Singapore.
Nitish V. Thakor is a Professor of Biomedical Engineering at Johns Hopkins University, Baltimore, USA, as well as the Director of the newly formed institute for neurotechnology, SiNAPSE, at the National University of Singapore.  Dr. Christopher Voigt is an Associate Professor in the Department of Biological Engineering at MIT, and is co-director of the Center for Integrative Synthetic Biology. Previously, he was a member of the faculty in the Department of Pharmaceutical Chemistry at University of California, San Francisco.
Dr. Christopher Voigt is an Associate Professor in the Department of Biological Engineering at MIT, and is co-director of the Center for Integrative Synthetic Biology. Previously, he was a member of the faculty in the Department of Pharmaceutical Chemistry at University of California, San Francisco.